
Как это ни странно, но людей делают счастливыми очень простые и понятные вещи. Простота и очевидность решений всегда восхищает значительно больше чем запутанная логика. И именно к таким решениям смело можно отнести нашу легкую, но технологичную разработку для распознавания транспортных и товарных накладных на основе сервиса ABBYY Cloud OCR.
В двух словах о том, что такое OCR (Optical Character Recognition). В деталях о сервисе можно узнать на сайте ABBYY, а по сути это инструмент «оцифровки» скан-копий оригиналов любых документов. Причем при хорошем качестве печати и сканирования удается распознать все до последней буквы документа, разложить по нужным полям, а дальше уже распоряжаться этими данными по своему усмотрению. В нашем случае разработка предназначена для обработки оригиналов подтверждающих документов от транспортных компаний и сопоставления с выполненными перевозками.
Почему же именно эта, технически не слишком сложная, разработка призвана буквально осчастливить рядовых логистов? Потому что разбор бумажных оригиналов первичных транспортных документов вручную в отсутствии всякой автоматизации и при хороших объемах перевозок — это адский и неблагодарный труд. Впрочем опытные логисты в курсе и точно оценят насколько круто хотя бы частично автоматизировать этот рутинный процесс.
Для начала, конечно, надо документы вручную разобрать и отсканировать, зато все остальное полностью (!) автоматически: распознавание, определение типа документа и ключевых полей, раскладывание файлов по папкам в хранилище, поиск соответствующей перевозки в ОТМ, прикрепление к ней документа и установка статуса на заказе о получении оригиналов.
Но обо всем по порядку!
Как выяснилось, главный залог успеха в деле распознавания — это аккуратность на всех этапах, начиная от сканирования. Вернее в идеале начинать надо еще раньше, с подготовки и печати самих первичных документов. А ОТМ как раз отлично приспособлен для того, чтобы даже при привлечении разных соисполнителей на разных участках пути дать им возможность распечатывать первичные документы. В этом случае сам документ будет аккуратно заполнен данными из системы и самое главное — его можно снабдить нашим номером или даже штрих-кодом, который гарантированно будет распознан при возврате документов.
Но даже если такого идеального сценария добиться не удалось — не беда, распознать документ можно по другим ссылочным номерам или по грузополучателю, наконец.

Первым делом полученные оригиналы документов необходимо разобрать на комплекты и отсканировать каждый в отдельный файл. Это самая трудоемкая и кропотливая часть процесса, но без нее никуда.
Мы взяли за основу три варианта возможных комплектов:
- Транспортная накладная (ТН)
- Транспортная накладная + Товарно-транспортная накладная (ТН + ТОРГ-12)
- Товарно-транспортная накладная (ТН + ТОРГ-12)
Каждый комплект может содержать и другие документы, хотя мы будем далее работать только с двумя первыми страницами. Но для архива сохраним все что есть, чтобы затем прикрепить к соответствующему заказу.
Когда со сканированием покончено можно приступать к творческому процессу автоматического распознавания и здесь на сцену выходит непревзойденный сервис от ABBYY.
Если есть шанс, что документы были подготовлены в нашей системе, тогда первым шагом мы попытаемся поискать на первой же странице наш родной штрих-код. Дело в том, что распознавание штрих-кодов в облачном сервисе ABBYY бесплатное, поэтому в случае успеха мы еще и сэкономим.
Если штрих-кода мы не обнаружили, то запускаем уже полное распознавание текста документа. Затем мы последовательно применяем известные нам шаблоны документов: сначала ТН, а потом ТОРГ-12. Шаблоны нужны для того, чтобы определить значения в конкретных ячейках документа. Ищем мы в первую очередь уникальные номера.
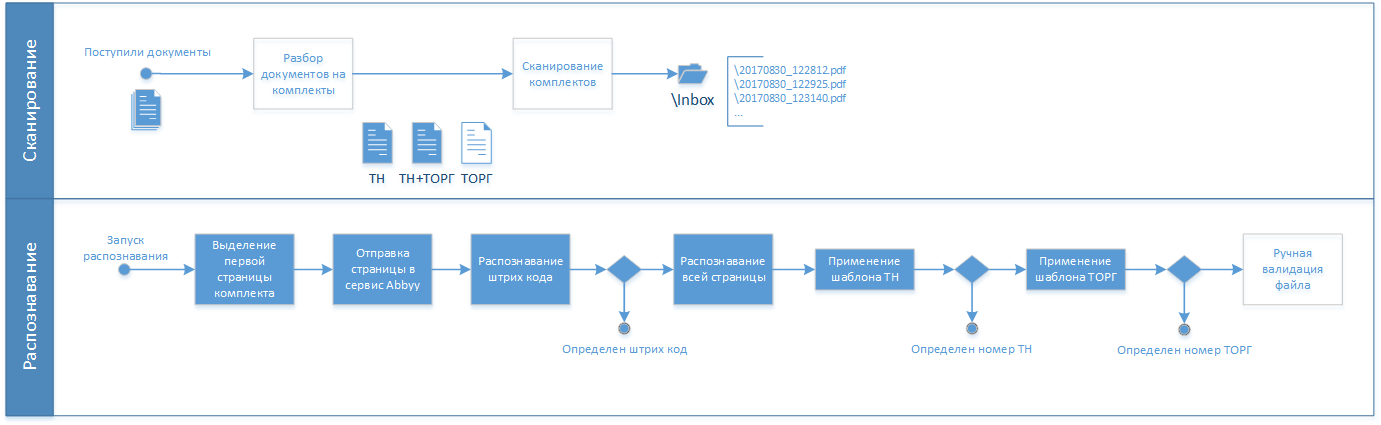
Но после этого этапа в нашей папке разбора могли остаться сиротливые файлы, которым не удалось присвоить уникальный номер в результате распознавания. Такие файлы придется открывать, внимательно всматриваться человеческим глазом и либо вычитывать плохо пропечатанный номер, либо разбираться по косвенным признакам что это за заказ. После этих упражнений и ручного переименования файла останется добросить его в папку к остальным собратьям, готовым к путешествию в ОТМ.
Наша конечная цель найти в ОТМ ту самую перевозку, исполнение которой подтверждает наш бумажный документ. Искать и сопоставлять будем по номеру или другим реквизитам, найденным на предыдущем шаге. Если удалось найти соответствующую перевозку, то из нее уже можно определить и все остальные данные: клиента, грузополучателя, дату. Это нужно для того, чтобы правильно заархивировать наш файл, разместив его в нужную папку, где его будет легко найти даже без необходимости заглядывать в ОТМ. В нашем случае структура каталога файлов очень простая: Клиент/Год/Месяц. Можно было бы еще разбить по направлениям перевозок, например.
Дальше остается только передать ссылку на наш файл в ОТМ в виде объекта Документ, прикрепить его к перевозке и установить ей статус получения оригиналов подтверждающих документов. При желании можно скопировать статус и на заказ тоже. Тут правда возможны разные варианты в случае многоплечевых перевозок.
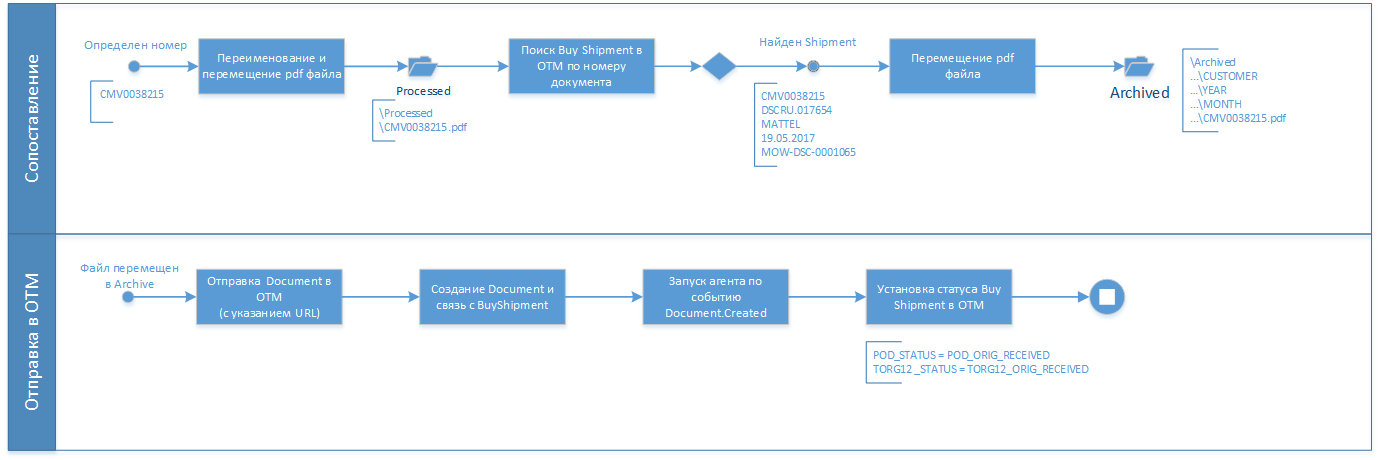
Прямо от перевозки в ОТМ можно будет перейти по ссылке и просмотреть связанный документ. А главное перевозки с таким статусом смело можно запускать в оплату. Мне же пора готовиться к обстоятельному рассказу на тему автоинвойсинга в ОТМ.